Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,是一个存储系统+计算框架的软件框架。主要解决海量数据存储与计算的问题,是大数据技术中的基石。Hadoop以一种可靠、高效、可伸缩的方式进行数据处理,用户可以在不了解分布式底层细节的情况下,开发分布式程序,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
Hadoop能解决什么问题
海量数据存储
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(High throughput)来访问数据,适合那些有着超大数据集(large data set)的应用程序,它由n台运行着DataNode的机器组成和1台(另外一个standby)运行NameNode进程一起构成。每个DataNode 管理一部分数据,然后NameNode负责管理整个HDFS 集群的信息(存储元数据)。
资源管理,调度和分配
Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
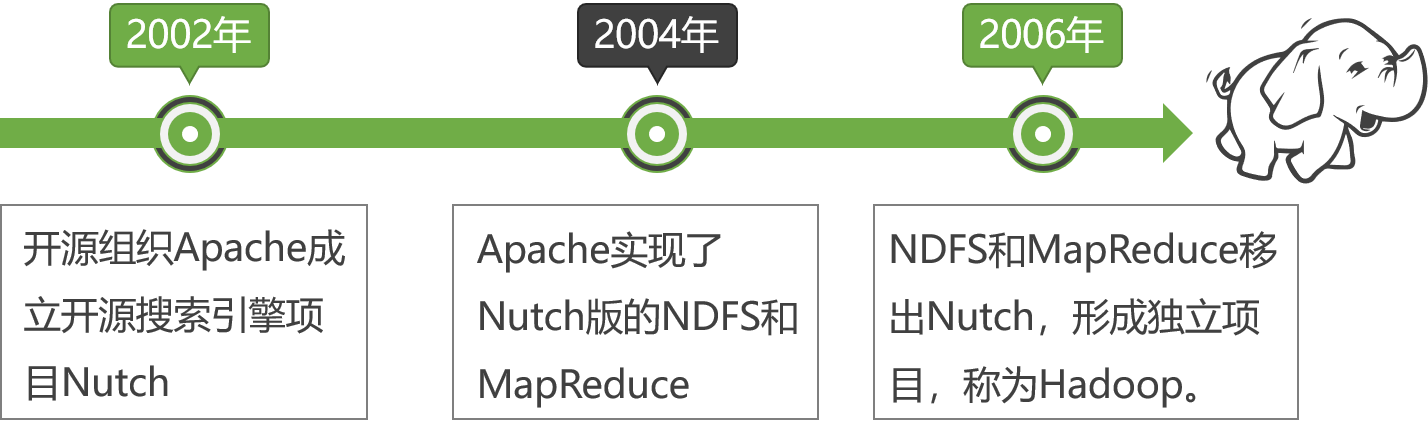
Hadoop的由来
Hadoop的核心架构
Hadoop的核心,说白了,就是HDFS和MapReduce。HDFS为海量数据提供了存储,而MapReduce为海量数据提供了计算框架。
HDFS
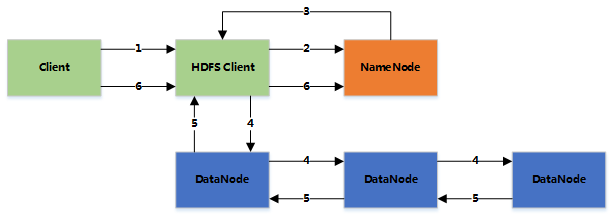
整个HDFS有三个重要角色:NameNode(名称节点)、DataNode(数据节点)和Client(客户机)。
典型的主从架构,用TCP/IP通信
NameNode:是Master节点(主节点),可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
DataNode:是Slave节点(从节点),是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
Client:切分文件;访问HDFS;与NameNode交互,获得文件位置信息;与DataNode交互,读取和写入数据。
还有一个Block(块)的概念:Block是HDFS中的基本读写单元;HDFS中的文件都是被切割为block(块)进行存储的;这些块被复制到多个DataNode中;块的大小(通常为64MB)和复制的块数量在创建文件时由Client决定。
MapReduce
MapReduce是一种分布式计算模型,它将大规模数据集(大于1TB)分成许多小数据块,然后在集群中的各个节点上进行并行处理,最后将结果汇总。MapReduce的计算过程可以分为两个阶段:Map阶段和Reduce阶段。
Map阶段:将输入数据切分成若干个小数据块,然后由多个Map任务并行处理,每个Map任务将处理结果输出为若干个键值对。
Reduce阶段:将Map阶段的输出结果按照键值对中的键进行分组,然后由多个Reduce任务并行处理,每个Reduce任务将处理结果输出为若干个键值对。
总结
Hadoop是一个分布式系统基础架构,主要解决海量数据存储与计算的问题。它的核心是HDFS和MapReduce,其中HDFS为海量数据提供了存储,而MapReduce为海量数据提供了计算框架。除此之外,Hadoop还有一个重要的组件——YARN,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
評論