前言
Vue.js模板功能强大,几乎可以满足我们在应用程序中所需的一切。但是,有一些场景下,比如基于输入或插槽值创建动态组件,render函数可以更好地满足这些用例。
那些来自React世界的开发者可能对render函数非常熟悉。通常在JSX中使用它们来构建React组件。虽然Vue渲染函数也可以用JSX编写,但我们将继续使用原始JS,有助于我们可以更轻松地了解Vue组件系统的基础。。
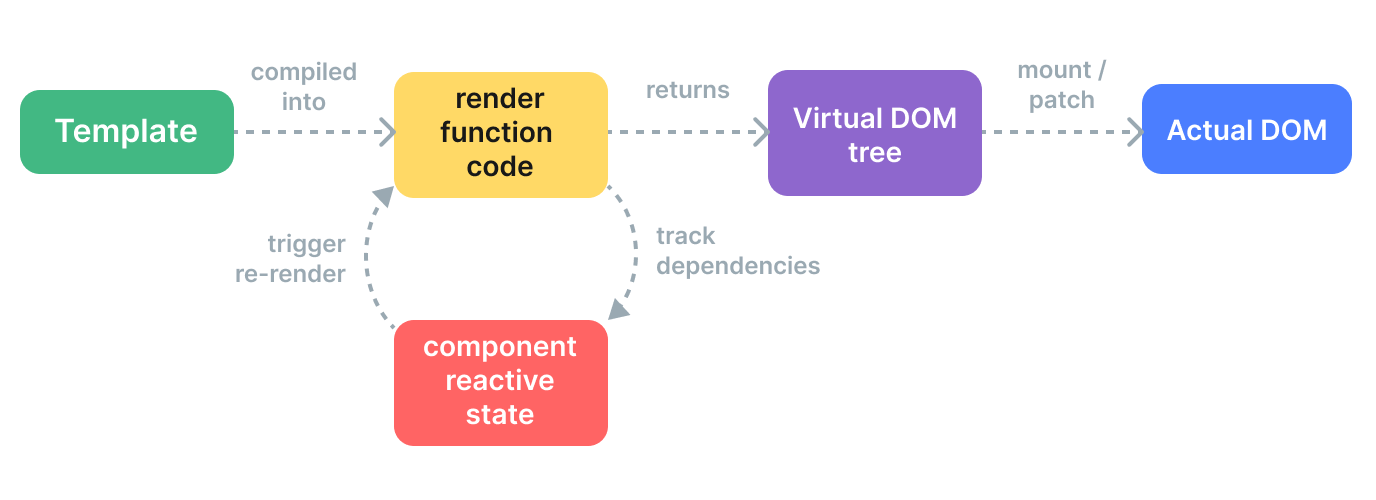
每个Vue组件都实现了一个render函数。大多数时候,该函数将由Vue编译器创建。当我们在组件上指定模板时,该模板的内容将由Vue编译器处理,编译器最终将返回render函数。渲染函数本质上返回一个虚拟DOM节点,该节点将被Vue在浏览器DOM中渲染。
现在又引出了虚拟DOM的概念, 虚拟DOM到底是什么?
虚拟文档对象模型(或”DOM”)允许Vue在更新浏览器之前在其内存中渲染组件。 这使一切变得更快,同时也避免了DOM重新渲染的高昂成本。因为每个DOM节点对象包含很多属性和方法,因此使用虚拟DOM预先在内存进行操作,可以省去很多浏览器直接创建DOM节点对象的开销。
Vue更新浏览器DOM时,会将更新的虚拟DOM与上一个虚拟DOM进行比较,并仅使用已修改的部分更新实际DOM。这意味着更少的元素更改,从而提高了性能。Render函数返回虚拟DOM节点,在Vue生态系统中通常称为VNode,该接口是允许Vue在浏览器DOM中写入这些对象的接口。它们包含使用Vue所需的所有信息。
挂载子节点和元素的属性
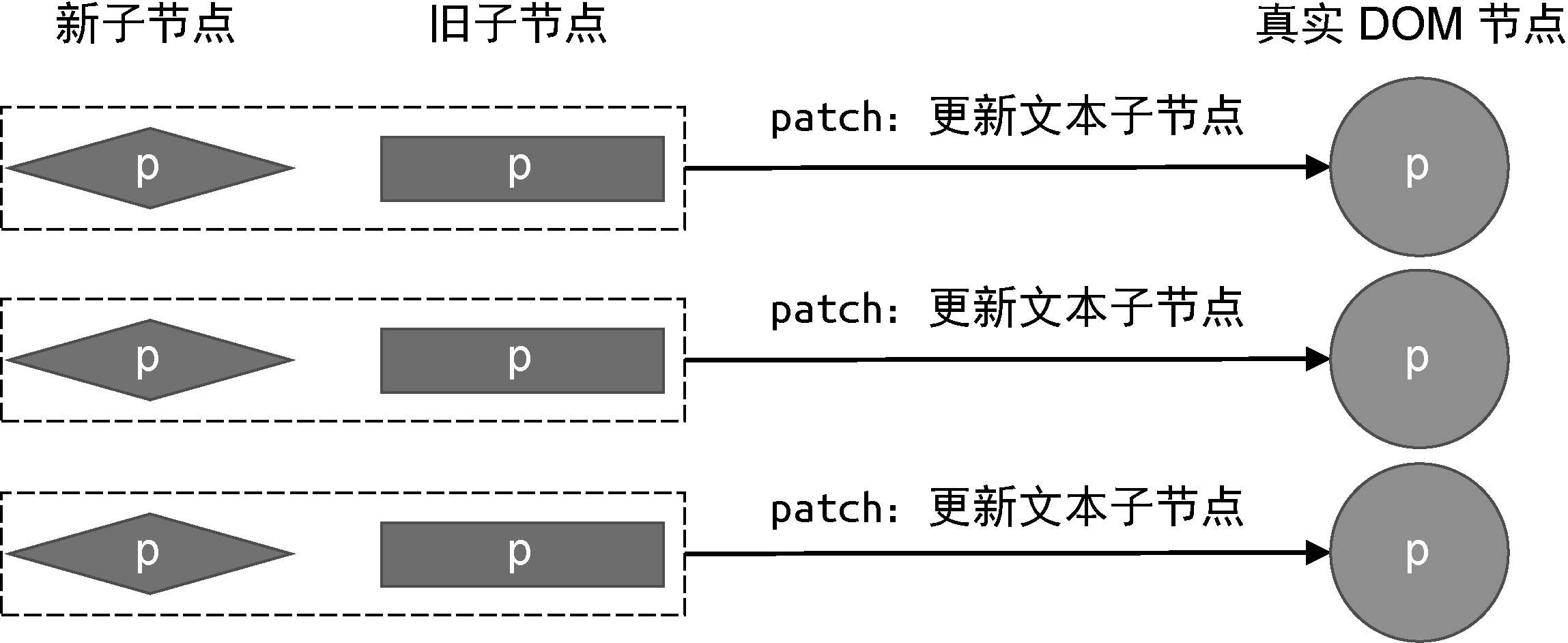
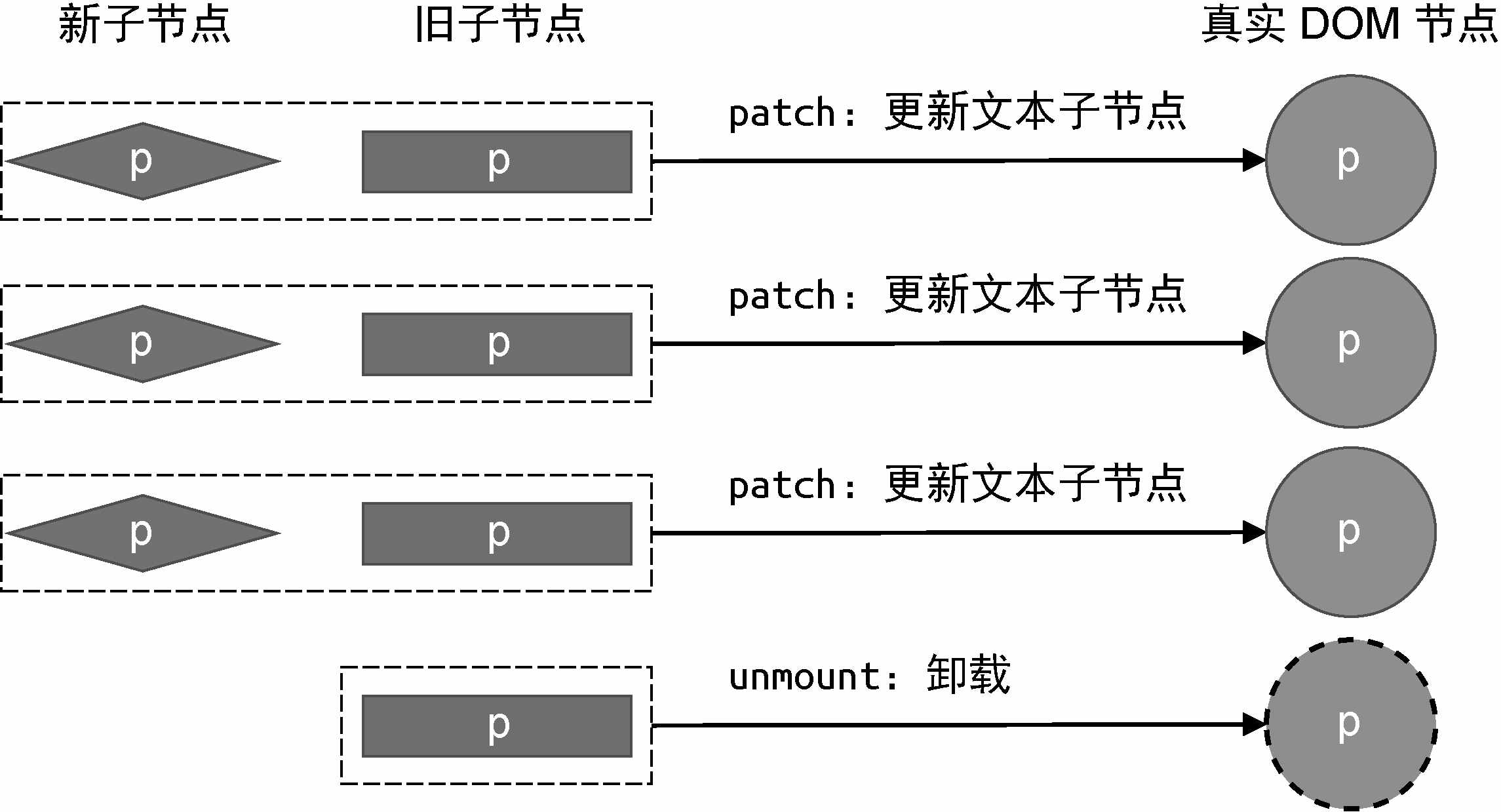
当vnode.children的值是字符串类型时,会把它设置为元素的文本内容。一个元素除了具有文本子节点外,还可以包含其他元素子节点,并且子节点可以是很多个。为了描述元素的子节点,我们需要将vnode.children定义为数组:
const vnode = {
type: 'div',
children: [
{
type: 'p',
children: 'hello'
}
]
};
上面这段代码描述的是“一个div标签具有一个子节点,且子节点是p标签”。可以看到,vnode.children是一个数组,它的每一个元素都是一个独立的虚拟节点对象。这样就形成了树型结构,即虚拟DOM树。
为了完成子节点的渲染,我们需要修改mountElement函数,如下面的代码所示:
function mountElement(vnode, container) {
const el = createElement(vnode.type);
if (typeof vnode.children === 'string') {
setElementText(el, vnode.children);
} else if (Array.isArray(vnode.children)) {
vnode.children.forEach(child => {
patch(null, child, el);
});
}
insert(el, container);
}
在上面这段代码中,我们增加了新的判断分支。使用Array.isArray函数判断vnode.children是否是数组,如果是数组,则循环遍历它,并调用patch函数挂载数组中的虚拟节点。在挂载子节点时,需要注意以下两点:
传递给patch函数的第一个参数是null。因为是挂载阶段,没有旧vnode,所以只需要传递null即可。这样,当patch函数执行时,就会递归地调用mountElement函数完成挂载。
传递给patch函数的第三个参数是挂载点。由于我们正在挂载的子元素是div标签的子节点,所以需要把刚刚创建的div元素作为挂载点,这样才能保证这些子节点挂载到正确位置。
完成了子节点的挂载后,我们再来看看如何用vnode描述一个标签的属性,以及如何渲染这些属性。我们知道,HTML标签有很多属性,其中有些属性是通用的,例如id、class等,而有些属性是特定元素才有的,例如form元素的action属性。实际上,渲染一个元素的属性比想象中要复杂,不过我们仍然秉承一切从简的原则,先来看看最基本的属性处理。
为了描述元素的属性,我们需要为虚拟DOM定义新的vnode.props字段,如下面的代码所示:
const vnode = {
type: 'div',
props: {
id: 'foo'
},
children: [
{
type: 'p',
children: 'hello'
}
]
};
vnode.props是一个对象,它的键代表元素的属性名称,它的值代表对应属性的值。这样,我们就可以通过遍历props对象的方式,把这些属性渲染到对应的元素上,如下面的代码所示:
function mountElement(vnode, container) {
const el = createElement(vnode.type);
if (vnode.props) {
for (const key in vnode.props) {
el.setAttribute(key, vnode.props[key]);
}
}
insert(el, container);
}
在这段代码中,我们首先检查了vnode.props字段是否存在,如果存在则遍历它,并调用setAttribute函数将属性设置到元素上。实际上,除了使用setAttribute函数为元素设置属性之外,还可以通过DOM对象直接设置:
function mountElement(vnode, container) {
const el = createElement(vnode.type);
if (vnode.props) {
for (const key in vnode.props) {
el[key] = vnode.props[key];
}
}
insert(el, container);
}
在这段代码中,我们没有选择使用setAttribute函数,而是直接将属性设置在DOM对象上,即el[key] = vnode.props[key]。实际上,无论是使用setAttribute函数,还是直接操作DOM对象,都存在缺陷。如前所述,为元素设置属性比想象中要复杂得多。不过,在讨论具体有哪些缺陷之前,我们有必要先搞清楚两个重要的概念:HTML Attributes和DOM Properties。
当我们处理元素属性时,有两种主要的方式:使用HTML Attributes和DOM Properties。这两者在概念上有些许不同:
HTML Attributes:
- HTML Attributes是在HTML标签中定义的属性,例如
id、class、src等。
- 通过
setAttribute方法可以设置HTML Attributes。
- HTML Attributes的值始终是字符串。
DOM Properties:
- DOM Properties是DOM对象上的属性,例如
element.id、element.className、element.src等。
- 直接操作DOM对象可以设置DOM Properties。
- DOM Properties的值可以是字符串、数字、布尔值等,具体取决于属性的类型。
HTML Attributes和DOM Properties
在处理元素属性时,我们需要明确HTML Attributes和DOM Properties之间的区别。
如果我们使用setAttribute方法设置属性,那么属性会被设置为HTML Attributes。如果我们直接操作DOM对象的属性,属性会被设置为DOM Properties。
现在,我们来讨论一下这两种方式存在的问题:
属性值类型转换问题:
- 当我们使用
setAttribute方法设置属性时,属性的值始终被转换为字符串。这就意味着,如果我们将一个数字或布尔值赋给属性,它们都会被转换为字符串。例如,element.setAttribute('value', 42)会将值转换为字符串'42'。
布尔属性问题:
- HTML中的一些属性是布尔属性,例如
checked、disabled等。对于这些属性,如果存在就表示为true,不存在就表示为false。
- 当我们使用
setAttribute方法设置布尔属性时,不论属性值是什么,都会被视为存在。例如,element.setAttribute('disabled', 'false')会使元素具有disabled属性,即使值是字符串'false'。
考虑到这些问题,最好的做法是尽量使用DOM Properties而不是HTML Attributes来设置元素的属性。这样可以避免类型转换问题和布尔属性问题,确保属性被正确设置。
首先,HTML Attributes指的是定义在HTML标签上的属性,例如id="my-input"、type="text"和value="foo"。当浏览器解析这段HTML代码后,会创建一个与之相符的DOM元素对象,我们可以通过JavaScript代码来读取该DOM对象:
const el = document.querySelector('#my-input');
现在来说一下DOM Properties。许多HTML Attributes在DOM对象上有与之同名的DOM Properties,例如id="my-input"对应el.id,type="text"对应el.type,value="foo"对应el.value等。但是,DOM Properties与HTML Attributes的名字并不总是一模一样的,例如:
<div class="foo"></div>
class="foo"对应的DOM Properties则是el.className。另外,并不是所有HTML Attributes都有与之对应的DOM Properties,例如:
<div aria-valuenow="75"></div>
aria-*类的HTML Attributes就没有与之对应的DOM Properties。
类似地,也不是所有DOM Properties都有与之对应的HTML Attributes,例如可以用el.textContent来设置元素的文本内容,但并没有与之对应的HTML Attributes来完成同样的工作。
HTML Attributes的值与DOM Properties的值之间是有关联的。例如下面的HTML片段:
<div id="foo"></div>
这个片段描述了一个具有id属性的div标签。其中,id="foo"对应的DOM Properties是el.id,并且值为字符串'foo'。我们把这种HTML Attributes与DOM Properties具有相同名称(即id)的属性看作直接映射。
但并不是所有HTML Attributes与DOM Properties之间都是直接映射的关系,例如:
<input value="foo" />
这是一个具有value属性的input标签。如果用户没有修改文本框的内容,那么通过el.value读取对应的DOM Properties的值就是字符串'foo'。而如果用户修改了文本框的值,那么el.value的值就是当前文本框的值。例如,用户将文本框的内容修改为'bar',那么:
console.log(el.value);
但如果运行下面的代码,会发生“奇怪”的现象:
console.log(el.getAttribute('value'));
console.log(el.value);
可以发现,用户对文本框内容的修改并不会影响el.getAttribute('value')的返回值,这个现象蕴含着HTML Attributes所代表的意义。实际上,HTML Attributes的作用是设置与之对应的DOM Properties的初始值。一旦值改变,那么DOM Properties始终存储着当前值,而通过getAttribute函数得到的仍然是初始值。
但我们仍然可以通过el.defaultValue来访问初始值,如下面的代码所示:
el.getAttribute('value');
el.value;
el.defaultValue;
这说明一个HTML Attributes可能关联多个DOM Properties。例如在上例中,value="foo"与el.value和el.defaultValue都有关联。
虽然我们可以认为HTML Attributes是用来设置与之对应的DOM Properties的初始值的,但有些值是受限制的,就好像浏览器内部做了默认值校验。如果你通过HTML Attributes提供的默认值不合法,那么浏览器会使用内建的合法值作为对应DOM Properties的默认值,例如:
<input type="foo" />
我们知道,为<input/>标签的type属性指定字符串'foo'是不合法的,因此浏览器会矫正这个不合法的值。所以当我们尝试读取el.type时,得到的其实是矫正后的值,即字符串'text',而非字符串'foo':
console.log(el.type);
从上述分析来看,HTML Attributes与DOM Properties之间的关系很复杂,但实际上我们只需要记住一个核心原则:HTML Attributes的作用是设置与之对应的DOM Properties的初始值。
如何正确地设置元素属性
在上文中,我们讨论了在Vue.js单文件组件的模板中,HTML Attributes和DOM Properties的设置方式。在普通的HTML文件中,浏览器会自动解析HTML Attributes并设置相应的DOM Properties。然而,在Vue.js的模板中,需要框架手动处理这些属性的设置。
首先,我们以一个禁用的按钮为例,如下所示的HTML代码:
<button disabled>Button</button>
浏览器会自动将这个按钮设置为禁用状态,并将其对应的DOM Properties el.disabled的值设置为true。但是,如果同样的代码出现在Vue.js的模板中,情况就会有所不同。
在Vue.js的模板中,HTML模板会被编译成虚拟节点(vnode),其中props.disabled的值是一个空字符串。如果直接使用setAttribute函数设置属性,会导致意外的效果,即按钮被禁用。例如,以下模板:
<button disabled="false">Button</button>
对应的虚拟节点为:
const button = {
type: 'button',
props: {
disabled: false
}
};
如果使用setAttribute函数将属性值设置为空字符串,实际上相当于:
el.setAttribute('disabled', '');
而按钮的el.disabled属性是布尔类型的,不关心具体的HTML Attributes的值是什么,只要disabled属性存在,按钮就会被禁用。因此,渲染器不应该总是使用setAttribute函数将vnode.props对象中的属性设置到元素上。
为了解决这个问题,我们可以优先设置元素的DOM Properties,但当值为空字符串时,需要手动将其矫正为true。以下是一个具体的实现示例:
function mountElement(vnode, container) {
const el = createElement(vnode.type);
if (vnode.props) {
for (const key in vnode.props) {
if (key in el) {
const type = typeof el[key];
const value = vnode.props[key];
if (type === 'boolean' && value === '') {
el[key] = true;
} else {
el[key] = value;
}
} else {
el.setAttribute(key, vnode.props[key]);
}
}
}
insert(el, container);
}
在上述代码中,我们检查每个vnode.props中的属性,看看是否存在对应的DOM Properties。如果存在,优先设置DOM Properties。同时,对布尔类型的DOM Properties做了值的矫正,即当要设置的值为空字符串时,将其矫正为布尔值true。如果vnode.props中的属性没有对应的DOM Properties,则仍然使用setAttribute函数完成属性的设置。
然而,上述实现仍然存在问题。有些DOM Properties是只读的,例如el.form。为了解决这个问题,我们可以添加一个辅助函数shouldSetAsProps,用于判断是否应该将属性作为DOM Properties设置。如果属性是只读的,或者需要特殊处理,就应该使用setAttribute函数来设置属性。
最后,为了使属性设置操作与平台无关,我们将属性设置相关的操作提取到渲染器选项中。以下是相应的代码示例:
const renderer = createRenderer({
createElement(tag) {
return document.createElement(tag);
},
setElementText(el, text) {
el.textContent = text;
},
insert(el, parent, anchor = null) {
parent.insertBefore(el, anchor);
},
patchProps(el, key, prevValue, nextValue) {
if (shouldSetAsProps(el, key, nextValue)) {
const type = typeof el[key];
if (type === 'boolean' && nextValue === '') {
el[key] = true;
} else {
el[key] = nextValue;
}
} else {
el.setAttribute(key, nextValue);
}
}
});
在mountElement函数中,只需要调用patchProps函数,并为其传递相应的参数即可。这样,我们就将属性相关的渲染逻辑从渲染器的核心中抽离出来,使其更加可维护和灵活。