引言
在谈到JIT前,还是需要对编译过程有一些简单的了解。
在编译原理中,把源代码翻译成机器指令,一般要经过以下几个重要步骤:
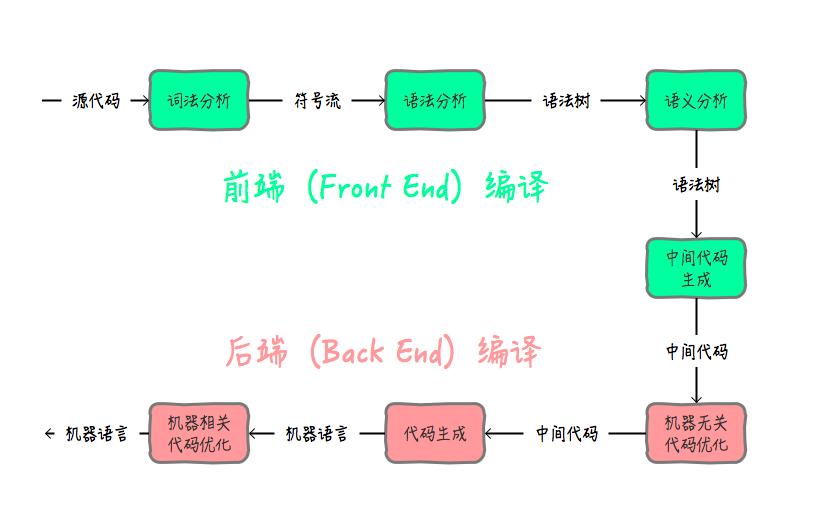
JIT简介
JIT是just in time的缩写,也就是即时编译。 通过JIT技术,能够做到Java程序执行速度的加速。那么,是怎么做到的呢?
我们都知道,Java是一门解释型语言(或者说是半编译,半解释型语言)。Java通过编译器javac先将源程序编译成与平台无关的Java字节码文件(.class),再由JVM解释执行字节码文件,从而做到平台无关。 但是,有利必有弊。对字节码的解释执行过程实质为:JVM先将字节码翻译为对应的机器指令,然后执行机器指令。很显然,这样经过解释执行,其执行速度必然不如直接执行二进制字节码文件。
而为了提高执行速度,便引入了 JIT 技术。当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”编译成本地机器相关的机器码,并进行优化,然后再把编译后的机器码缓存起来,以备下次使用。
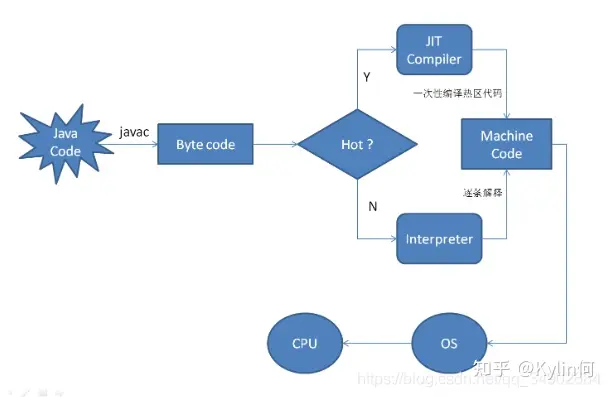
Hot Spot编译
当 JVM 执行代码时,它并不是立即开始编译代码的。这主要有两个原因:
首先,如果这段代码本身在将来只会被执行一次,那么从本质上看,编译就是在浪费精力。因为将代码翻译成 java 字节码相对于编译这段代码并执行代码来说,要快很多。
当然,如果一段代码频繁的调用方法,或是一个循环,也就是这段代码被多次执行,那么编译就非常值得了。因此,编译器具有的这种权衡能力会首先执行解释后的代码,然后再去分辨哪些方法会被频繁调用来保证其本身的编译。Hot Spot VM 采用了 JIT compile 技术,将运行频率很高的字节码直接编译为机器指令执行以提高性能 ,所以当字节码被 JIT 编译为机器码的时候,要说它是编译执行的也可以。也就是说,运行时,部分代码可能由 JIT 翻译为目标机器指令(以 method 为翻译单位,还会保存起来,第二次执行就不用翻译了)直接执行。
第二个原因是最优化,当 JVM 执行某一方法或遍历循环的次数越多,就会更加了解代码结构,那么 JVM 在编译代码的时候就做出相应的优化。
JavaScript 编译 - JIT (just-in-time) compiler 是怎么工作的
大体来说,有两种方式可以将程序翻译成机器可执行的指令,使用编译器 (Compiler) 或者是 解释器 (Interpreter)。
解释器
解释器是边翻译,边执行。
优缺点
- 优点:快速执行,不需要等待编译
- 缺点:相同的代码可能被翻译多次,比如循环内部的代码
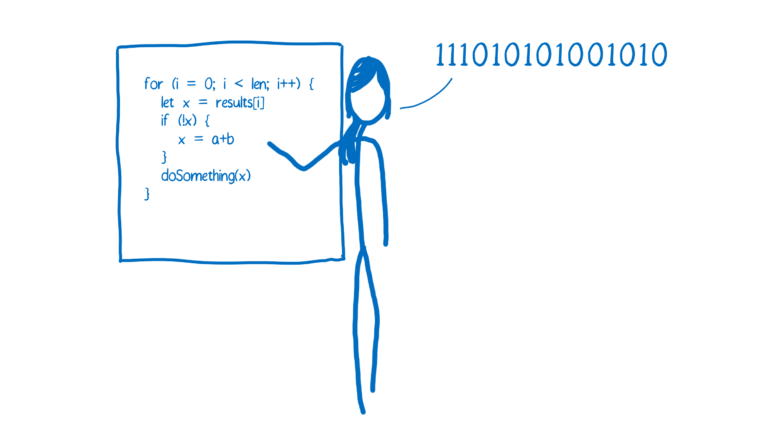
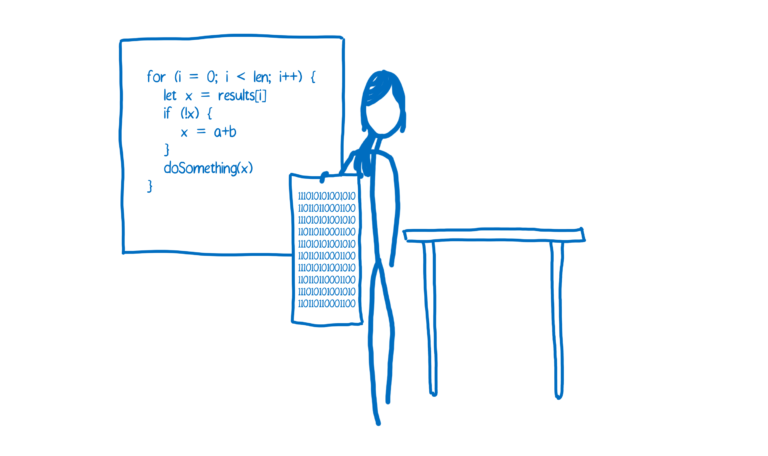
编译器
而编译器则是提前将结果翻译出来,并生成一个可执行程序。
优缺点
- 优点:不需要重复编译,并且可以在编译时对代码做优化
- 缺点:需要提前编译
JIT
JavaScript 刚出现的时候,是一个典型的解释型语言,因此运行速度极慢,后来浏览器引入了 JIT compiler,大幅提高了 JavaScript 的运行速度。
原理:They added a new part to the JavaScript engine, called a monitor (aka a profiler). That monitor watches the code as it runs, and makes a note of how many times it is run and what types are used.
简单来说,浏览器在 JavaScript engine 中加入了一个 monitor,用来观察运行的代码。并记录下每段代码运行的次数和代码中的变量的类型。
那么问题来了,为什么这样做能提高运行速度?
后面的所有内容都以下面这个函数的运行为例:
function arraySum(arr) {
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}1st step - Interpreter
一开始只是简单的使用解释器执行,当某一行代码被执行了几次,这行代码会被打上 Warm 的标签;当某一行代码被执行了很多次,这行代码会被打上 Hot 的标签
2nd step - Baseline compiler
被打上 Warm 标签的代码会被传给Baseline Compiler编译且储存,同时按照行数 (Line number) 和变量类型 (Variable type) 被索引(为什么会引入变量类型做索引很重要,后面会讲)
当发现执行的代码命中索引,会直接取出编译后的代码执行,从而不需要重复编译已经编译过的代码
3rd step - Optimizing compiler
被打上 Hot 标签的代码会被传给 Optimizing compiler,这里会对这部分带码做更优化的编译。怎么样做更优化的编译呢?关键点就在这里,没有别的办法,只能用概率模型做一些合理的 假设 (Assumptions)。
比如我们上面的循环中的代码 sum += arr[i],尽管这里只是简单的 + 运算和赋值,但是因为 JavaScript 的动态类型 (Dynamic typing),对应的编译结果有很多种可能(这个角度能很明显的暴露动态类型的缺点)
比如:
sum 是 Int,arr 是 Array,i 是 Int,这里的 + 就是加法运算,对应其中一种编译结果
sum 是 string,arr 是 Array,i 是 Int,这里的 + 就是字符串拼接,并且需要把 i 转换为 string 类型
…
下面的图可以看出,这么简单的一行代码对应有 2^4 = 16 种可能的编译结果
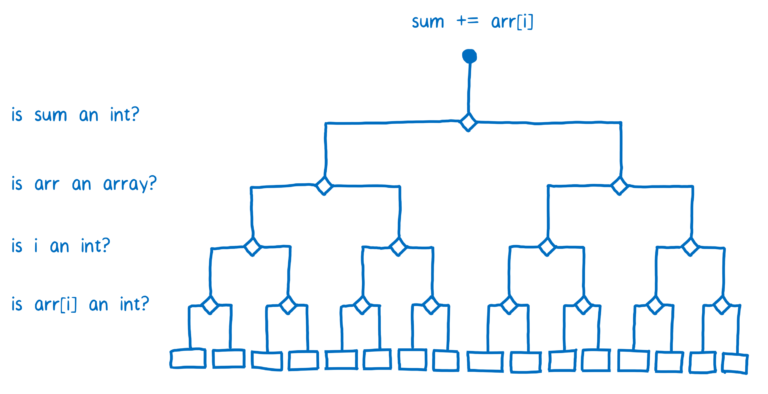
前面第二步的 Baseline compiler 做的就是这件事,所以上面说编译后的代码需要使用line number和variable type一起做索引,因为不同的 variable type 对应不同的编译结果。
如果代码是 “Warm” 的,JIT 的任务也就到此为止,后面每次执行的时候,需要先判断类型,再使用对应类型的编译结果就好。
但是上面我们说,当代码变成 “hot” 的时候,会做更多的优化。这里的优化其实指的就是 JIT 直接假设一个前提,比如这里我们直接假设 sum 是 Int,i 也是 Int,arr 是 Array,于是就只用一种编译结果就好了。
实际上,在执行前会做类型检查,看是假设是否成立,如果不成立执行就会被打回interpreter或者baseline compiler的版本,这个操作叫做 "反优化 (deoptimization)"。
可以看出,只要假设的成功率足够高,那么代码的执行速度就会快。但是如果假设的成功率很低,那么会导致比没有任何优化的时候还要慢(因为要经历optimize => deoptimize的过程)
结论
简而言之,这就是 JIT运行时所做的事情。它通过监控正在运行的代码并发送要优化的热代码路径,使 JavaScript 运行得更快。这使得大多数 JavaScript 应用程序的性能提高了许多倍。
然而,即使有了这些改进,JavaScript 的性能仍然无法预测。为了使速度更快,JIT 在运行时增加了一些开销,包括:
优化和反优化
用于监视器和发生信息丢失时恢复信息的内存
用于存储函数的基线和优化版本的内存
这里还有改进的空间:可以消除开销,使性能更加可预测。