What is Hadoop?
Hadoop is a distributed system infrastructure developed by the Apache Foundation. It is a software framework that combines a storage system and a computing framework. It mainly solves the problem of storing and computing massive data and is the cornerstone of big data technology. Hadoop processes data in a reliable, efficient, and scalable way. Users can develop distributed programs on Hadoop without understanding the underlying details of the distributed system. Users can easily develop and run applications that process massive data on Hadoop.
What problems can Hadoop solve?
Massive data storage
HDFS has high fault tolerance and is designed to be deployed on low-cost hardware. It provides high throughput for accessing data and is suitable for applications with large data sets. It consists of n machines running DataNode and one machine running NameNode (another standby). Each DataNode manages a portion of the data, and NameNode is responsible for managing the information (metadata) of the entire HDFS cluster.
Resource management, scheduling, and allocation
Apache Hadoop YARN(Yet Another Resource Negotiator) is a new Hadoop resource manager. It is a general resource management system and scheduling platform that provides unified resource management and scheduling for upper-layer applications. Its introduction has brought huge benefits to the cluster in terms of utilization, unified resource management, and data sharing.
The origin of Hadoop
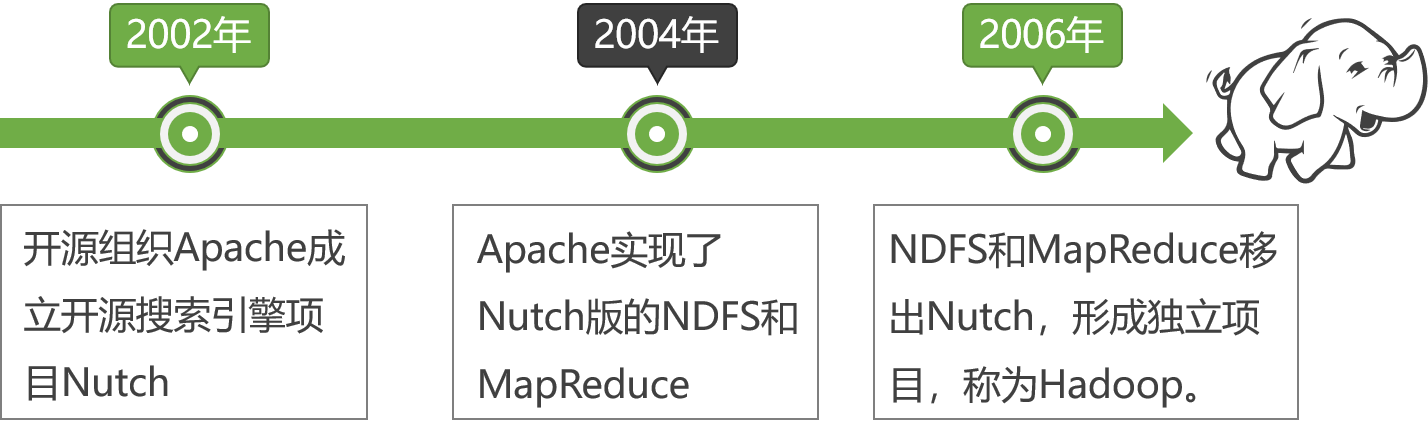
The core architecture of Hadoop
The core of Hadoop is HDFS and MapReduce. HDFS provides storage for massive data, and MapReduce provides a computing framework for massive data.
HDFS
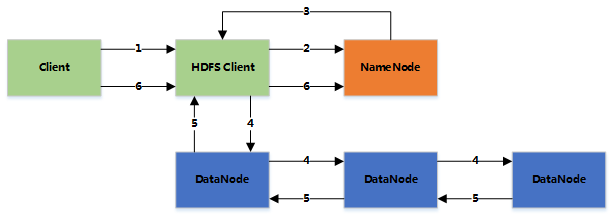
The entire HDFS has three important roles: NameNode, DataNode, and Client.
Typical master-slave architecture, using TCP/IP communication.
NameNode: The master node of the distributed file system, responsible for managing the namespace of the file system, cluster configuration information, and storage block replication. The NameNode stores the metadata of the file system in memory, including file information, block information for each file, and information about each block in the DataNode.
DataNode: The slave node of the distributed file system, which is the basic unit of file storage. It stores blocks in the local file system and saves the metadata of the blocks. It also periodically sends information about all existing blocks to the NameNode.
Client: Splits files, accesses HDFS, interacts with the NameNode to obtain file location information, and interacts with the DataNode to read and write data.
There is also the concept of a block: a block is the basic read and write unit in HDFS. Files in HDFS are stored as blocks, which are replicated to multiple DataNodes. The size of a block (usually 64MB) and the number of replicated blocks are determined by the client when the file is created.
MapReduce
MapReduce is a distributed computing model that divides large data sets (greater than 1TB) into many small data blocks, and then performs parallel processing on various nodes in the cluster, and finally aggregates the results. The MapReduce calculation process can be divided into two stages: the Map stage and the Reduce stage.
Map stage: The input data is divided into several small data blocks, and then multiple Map tasks process them in parallel. Each Map task outputs the processing result as several key-value pairs.
Reduce stage: The output results of the Map stage are grouped according to the keys in the key-value pairs, and then multiple Reduce tasks process them in parallel. Each Reduce task outputs the processing result as several key-value pairs.
Summary
Hadoop is a distributed system infrastructure that mainly solves the problem of storing and computing massive data. Its core is HDFS and MapReduce, where HDFS provides storage for massive data, and MapReduce provides a computing framework for massive data. In addition, Hadoop also has an important component-YARN, which is a general resource management system and scheduling platform that provides unified resource management and scheduling for upper-layer applications.
Comments