Definition of MapReduce
MapReduce is a programming framework for distributed computing programs. It is the core framework for developing “Hadoop-based data analysis applications”. Its core function is to integrate the user’s written business logic code and default components into a complete distributed computing program, which runs concurrently on a Hadoop cluster.
Reason for the Emergence of MapReduce
Why do we need MapReduce?
- Massive data cannot be processed on a single machine due to hardware resource limitations.
- Once the single-machine version of the program is extended to run on a cluster, it will greatly increase the complexity and development difficulty of the program.
- With the introduction of the MapReduce framework, developers can focus most of their work on the development of business logic, while leaving the complexity of distributed computing to the framework to handle.
Consider a word count requirement in a scenario with massive data:
- Single-machine version: limited memory, limited disk, limited computing power
- Distributed: file distributed storage (HDFS), computing logic needs to be divided into at least two stages (one stage is independently concurrent, one stage is converged), how to distribute computing programs, how to allocate computing tasks (slicing), how to start the two-stage program? How to coordinate? Monitoring during the entire program running process? Fault tolerance? Retry?
It can be seen that when the program is extended from a single-machine version to a distributed version, a large amount of complex work will be introduced.
Relationship between MapReduce and Yarn
Yarn is a resource scheduling platform that is responsible for providing server computing resources for computing programs, which is equivalent to a distributed operating system platform. MapReduce and other computing programs are like application programs running on top of the operating system.
Important concepts of YARN:
- Yarn does not know the running mechanism of the program submitted by the user;
- Yarn only provides scheduling of computing resources (when the user program applies for resources from Yarn, Yarn is responsible for allocating resources);
- The supervisor role in Yarn is called ResourceManager;
- The role that specifically provides computing resources in Yarn is called NodeManager;
- In this way, Yarn is completely decoupled from the running user program, which means that various types of distributed computing programs (MapReduce is just one of them), such as MapReduce, storm programs, spark programs, tez, etc., can run on Yarn;
- Therefore, computing frameworks such as Spark and Storm can be integrated to run on Yarn, as long as they have resource request mechanisms that comply with Yarn specifications in their respective frameworks;
- Yarn becomes a universal resource scheduling platform. From then on, various computing clusters that previously existed in enterprises can be integrated on a physical cluster to improve resource utilization and facilitate data sharing.
MapReduce Working Principle
Strictly speaking, MapReduce is not an algorithm, but a computing idea. It consists of two stages: map and reduce.
MapReduce Process
To improve development efficiency, common functions in distributed programs can be encapsulated into frameworks, allowing developers to focus on business logic.
MapReduce is such a general framework for distributed programs, and its overall structure is as follows (there are three types of instance processes during distributed operation):
- MRAppMaster: responsible for the process scheduling and status coordination of the entire program
- MapTask: responsible for the entire data processing process of the map phase
- ReduceTask: responsible for the entire data processing process of the reduce phase
MapReduce Mechanism
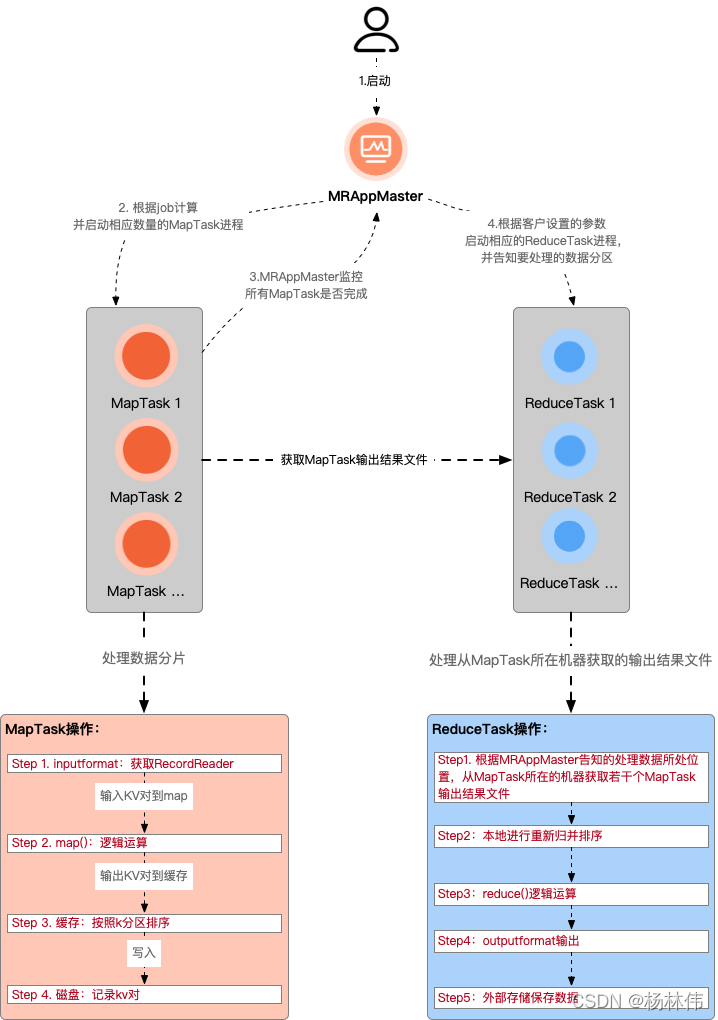
The process is described as follows:
When an MR program starts, the MRAppMaster is started first. After the MRAppMaster starts, according to the description information of this job, it calculates the number of MapTask instances required and applies to the cluster to start the corresponding number of MapTask processes.
After the MapTask process is started, data processing is performed according to the given data slice range. The main process is:
- Use the inputformat specified by the customer to obtain the RecordReader to read the data and form input KV pairs;
- Pass the input KV pairs to the customer-defined map() method for logical operation, and collect the KV pairs output by the map() method to the cache;
- Sort the KV pairs in the cache according to K partition and continuously overflow to the disk file.
After the MRAppMaster monitors that all MapTask process tasks are completed, it will start the corresponding number of ReduceTask processes according to the customer-specified parameters, and inform the ReduceTask process of the data range (data partition) to be processed.
After the ReduceTask process is started, according to the location of the data to be processed notified by the MRAppMaster, it obtains several MapTask output result files from several machines where the MapTask is running, and performs re-merging and sorting locally. Then, groups the KV with the same key into one group, calls the customer-defined reduce() method for logical operation, collects the result KV output by the operation, and then calls the customer-specified outputformat to output the result data to external storage.
Let’s take an example.
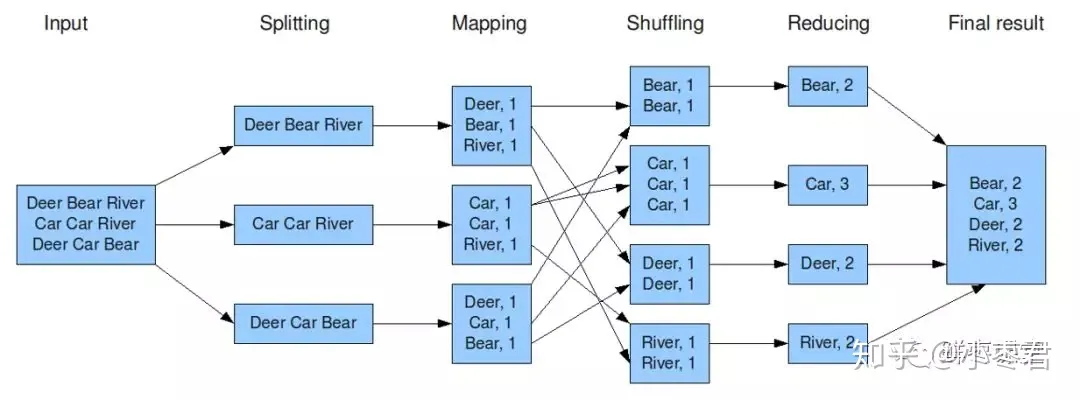
The above figure shows a word frequency counting task.
Hadoop divides the input data into several slices and assigns each split to a map task for processing.
After mapping, each word and its frequency in this task are obtained.
Shuffle puts the same words together, sorts them, and divides them into several slices.
According to these slices, reduce is performed.
The result of the reduce task is counted and output to a file.
In MapReduce, two roles are required to complete these processes: JobTracker and TaskTracker.
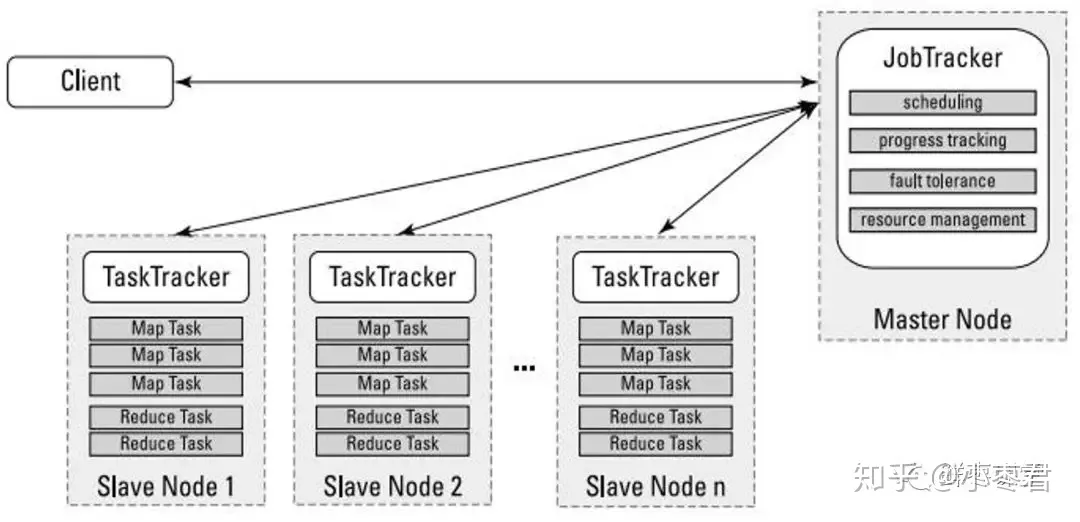
JobTracker is used to schedule and manage other TaskTrackers. JobTracker can run on any computer in the cluster. TaskTracker is responsible for executing tasks and must run on DataNode.
Here is a simple MapReduce implementation example:
It is used to count the number of occurrences of each word in the input file.
Import necessary packages:
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;Define the Mapper class:
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> { protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); // Split each line of text into words and send them to the Reducer String[] words = line.split("\\s+"); for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } }The Mapper class is responsible for splitting the input text data into words and outputting a key-value pair (word, 1) for each word.
Define the Reducer class:
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> { protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; // Accumulate the number of occurrences of the same word for (IntWritable value : values) { sum += value.get(); } // Output the word and its total number of occurrences context.write(key, new IntWritable(sum)); } }The Reducer class receives key-value pairs from the Mapper, accumulates the values of the same key, and then outputs the word and its total number of occurrences.
Main function (main method):
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(word.class); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // Set the input and output paths FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Submit the job and wait for it to complete job.waitForCompletion(true); }
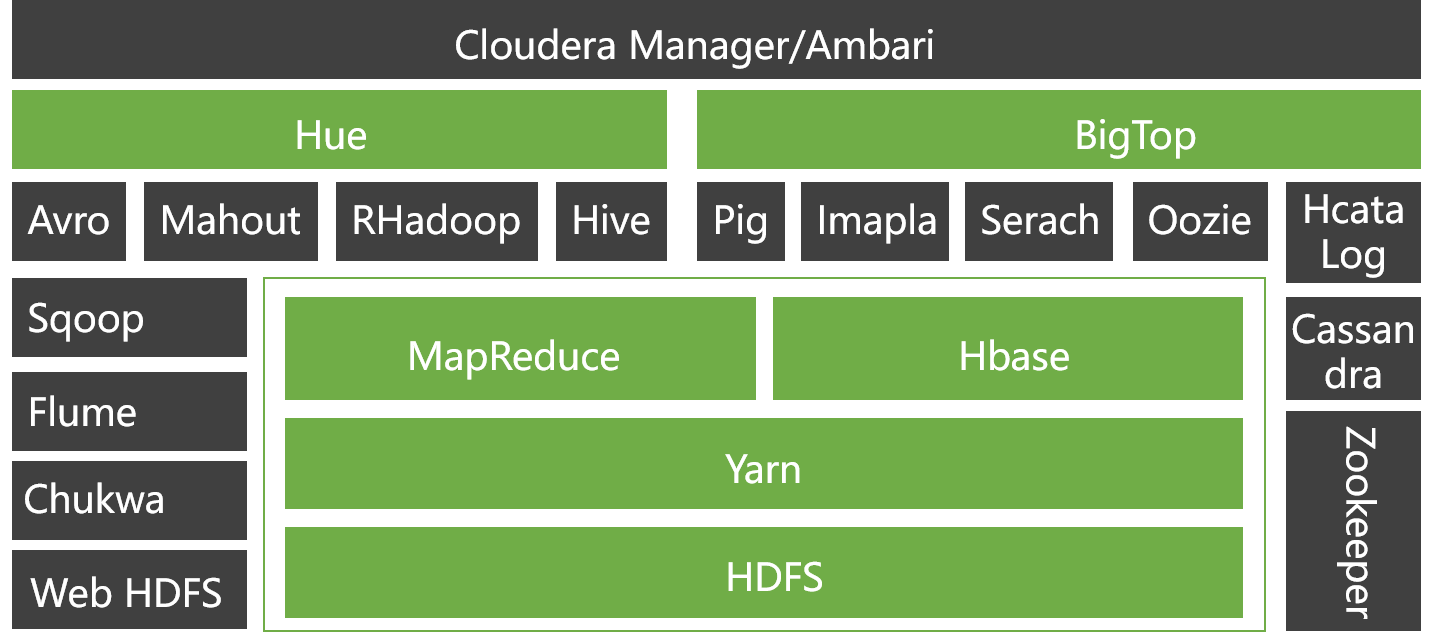
In the entire Hadoop architecture, the computing framework plays a crucial role, on the one hand, it can operate on the data in HDFS, on the other hand, it can be encapsulated to provide calls from upper-level components such as Hive and Pig.
Let’s briefly introduce some of the more important components.
HBase: originated from Google’s BigTable; it is a highly reliable, high-performance, column-oriented, and scalable distributed database.
Hive: is a data warehouse tool that can map structured data files to a database table, and quickly implement simple MapReduce statistics through SQL-like statements, without the need to develop dedicated MapReduce applications, which is very suitable for statistical analysis of data warehouses.
Pig: is a large-scale data analysis tool based on Hadoop. It provides a SQL-LIKE language called Pig Latin. The compiler of this language converts SQL-like data analysis requests into a series of optimized MapReduce operations.
ZooKeeper: originated from Google’s Chubby; it is mainly used to solve some data management problems frequently encountered in distributed applications, simplifying the difficulty of coordinating and managing distributed application.
Ambari: Hadoop management tool, which can monitor, deploy, and manage clusters quickly.
Sqoop: used to transfer data between Hadoop and traditional databases.
Mahout: an extensible machine learning and data mining library.
Advantages and Applications of Hadoop
Overall, Hadoop has the following advantages:
High reliability: This is determined by its genes. Its genes come from Google. The best thing Google is good at is “garbage utilization.” When Google started, it was poor and couldn’t afford high-end servers, so it especially likes to deploy this kind of large system on ordinary computers. Although the hardware is unreliable, the system is very reliable.
High scalability: Hadoop distributes data and completes computing tasks among available computer clusters, and these clusters can be easily expanded. In other words, it is easy to become larger.
High efficiency: Hadoop can dynamically move data between nodes and ensure dynamic balance of each node, so the processing speed is very fast.
High fault tolerance: Hadoop can automatically save multiple copies of data and automatically redistribute failed tasks. This is also considered high reliability.
Low cost: Hadoop is open source and relies on community services, so the cost of use is relatively low.
Based on these advantages, Hadoop is suitable for applications in large data storage and large data analysis, suitable for running on clusters of several thousand to tens of thousands of servers, and supports PB-level storage capacity.
Hadoop’s applications are very extensive, including: search, log processing, recommendation systems, data analysis, video and image analysis, data storage, etc., can be deployed using it.
Comments