What is Hadoop Yarn?
In the ancient Hadoop 1.0, the JobTracker of MapReduce was responsible for too many tasks, including resource scheduling and managing numerous TaskTrackers. This was naturally unreasonable. Therefore, during the upgrade process from 1.0 to 2.0, Hadoop separated the resource scheduling work of JobTracker and made it an independent resource management framework, which directly made Hadoop the most stable cornerstone in big data. This independent resource management framework is Yarn.
Before we introduce Yarn in detail, let’s briefly talk about Yarn. The full name of Yarn is “Yet Another Resource Negotiator”, which means “another resource scheduler”. This naming is similar to “Have a Nice Inn”. Here’s a little more information: there used to be a Java project compilation tool called Ant, which was named similarly, “Another Neat Tool” in abbreviation, which means “another organizing tool”.
Since it is called a resource scheduler, its function is naturally responsible for resource management and scheduling. Next, let’s take a closer look at Yarn.
Yarn Architecture
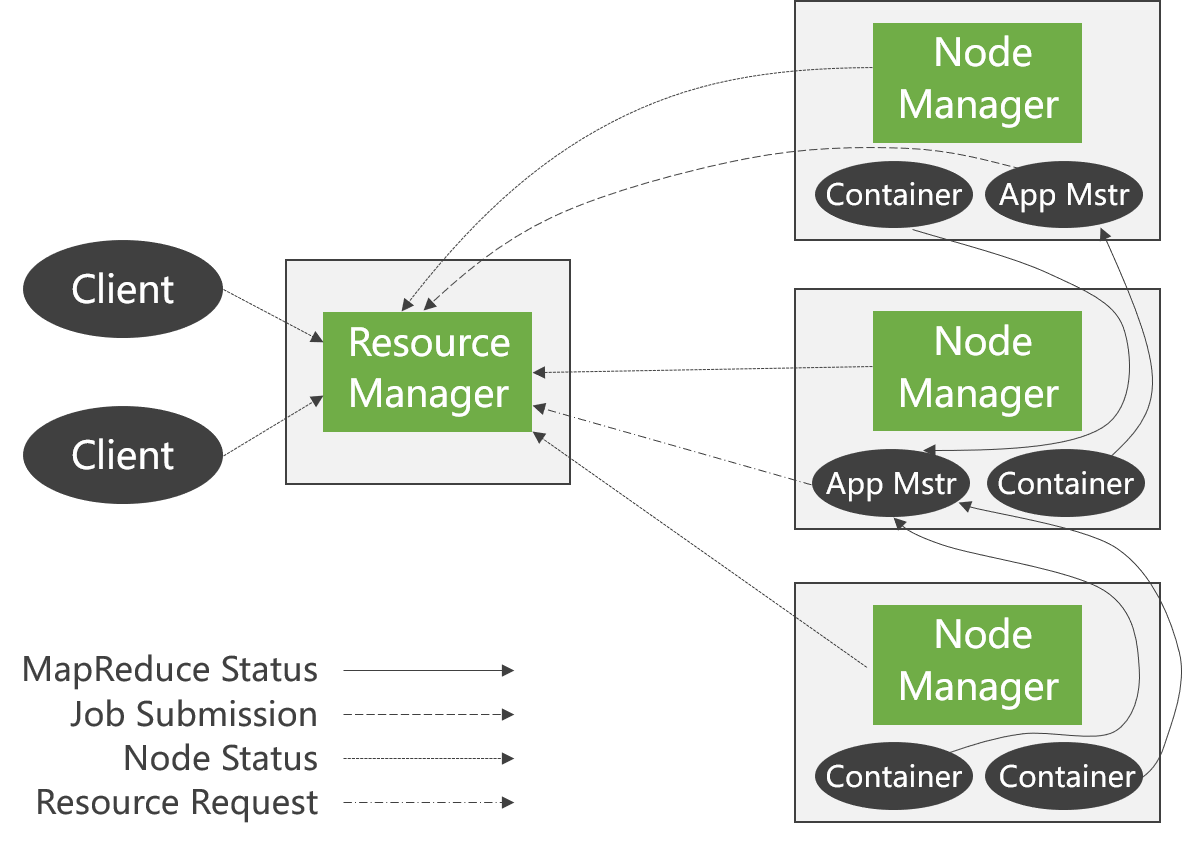
① Client: The client is responsible for submitting jobs to the cluster.
② ResourceManager: The main process of the cluster, the arbitration center, is responsible for cluster resource management and task scheduling.
③ Scheduler: Resource arbitration module.
④ ApplicationManager: Selects, starts, and supervises the ApplicationMaster.
⑤ NodeManager: The cluster’s secondary process, which manages and monitors Containers and executes specific tasks.
⑥ Container: A collection of local resources, such as a Container with 4 CPUs and 8GB of memory.
⑦ ApplicationMaster: The task execution and supervision center.
Three Main Components
Looking at the top of the figure, we can intuitively see two main components, ResourceManager and NodeManager, but there is actually an ApplicationMaster that is not displayed in the figure. Let’s take a look at these three components separately.
ResourceManager
Let’s start with the ResourceManager in the center of the figure. From the name, we can know that this component is responsible for resource management, and there is only one ResourceManager in the entire system to be responsible for resource scheduling.
It also includes two main components: the Scheduler and the ApplicationManager.
The Scheduler: Essentially, the Scheduler is a strategy or algorithm. When a client submits a task, it allocates resources based on the required resources and the current state of the cluster. Note that it only allocates resources to the application and does not monitor the status of the application.
ApplicationManager: Similarly, you can roughly guess what it does from its name. The ApplicationManager is responsible for managing the applications submitted by the client. Didn’t we say that the Scheduler does not monitor the program submitted by the user? In fact, the monitoring of the application is done by the ApplicationManager.
ApplicationMaster
Every time a client submits an Application, a new ApplicationMaster is created. This ApplicationMaster applies to the ResourceManager for container resources, sends the program to be run to the container after obtaining the resources, and then performs distributed computing.
This may be a bit difficult to understand. Why send the running program to the container? If you look at it from a traditional perspective, the program runs still, and data flows in and out constantly. But when the data volume is large, it cannot be done because the cost of moving massive data is too high and takes too long. However, there is an old Chinese saying that “if the mountain will not come to Muhammad, then Muhammad must go to the mountain.” This is the idea of big data distributed computing. Since big data is difficult to move, I will publish the application program that is easy to move to each node for calculation. This is the idea of big data distributed computing.
NodeManager
The NodeManager is a proxy for the ResourceManager on each machine, responsible for container management, monitoring their resource usage (CPU, memory, disk, and network, etc.), and providing these resource usage reports to the ResourceManager/Scheduler.
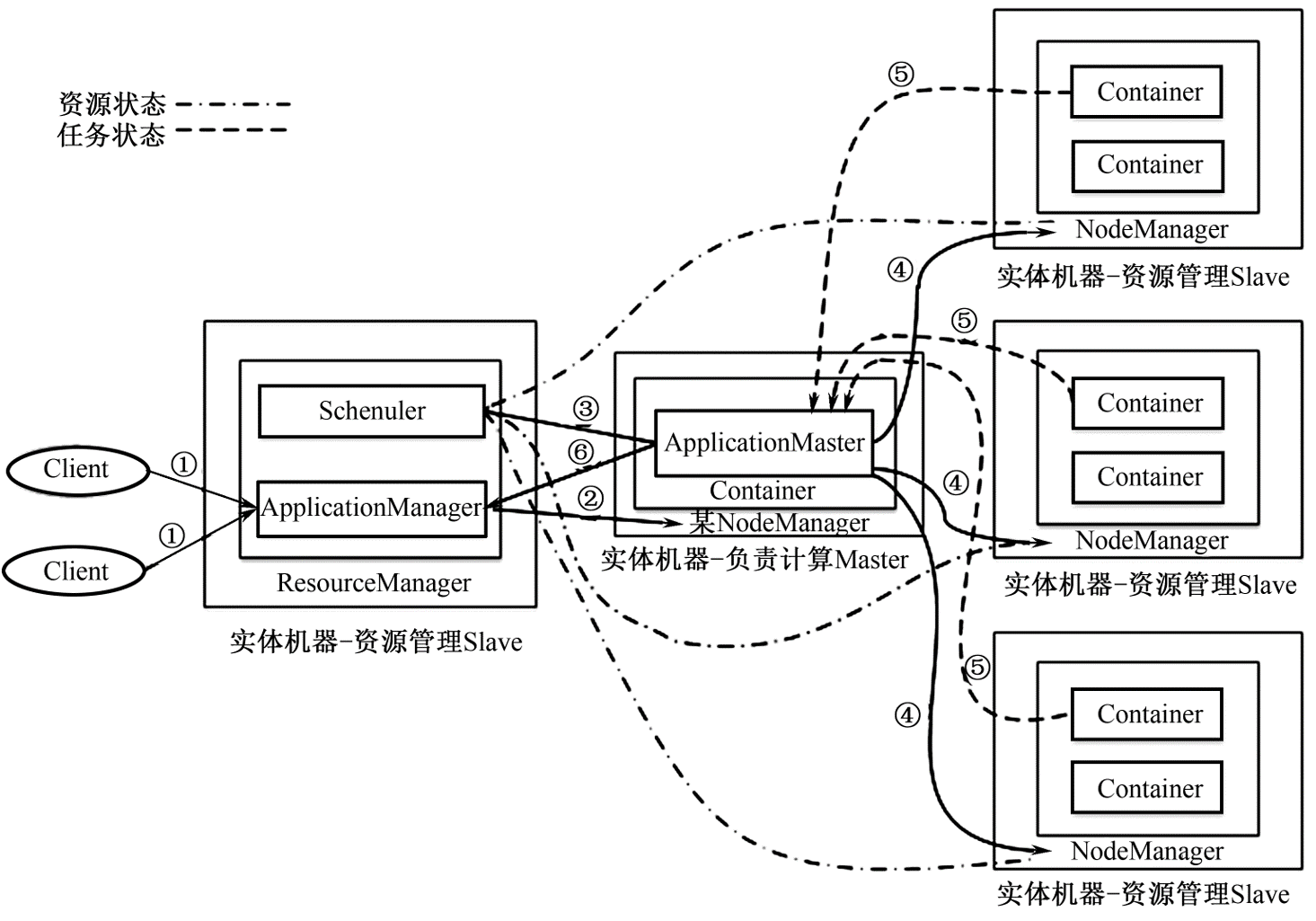
The main idea of Yarn is to split the two functions of resource management and task scheduling of MRv1 JobTracker into two independent processes:

Yarn is still a master/slave structure.
The main process ResourceManager is the resource arbitration center of the entire cluster.
The secondary process NodeManager manages local resources.
ResourceManager and the subordinate node process NodeManager form the Hadoop 2.0 distributed data computing framework.
The Process of Submitting an Application to Yarn
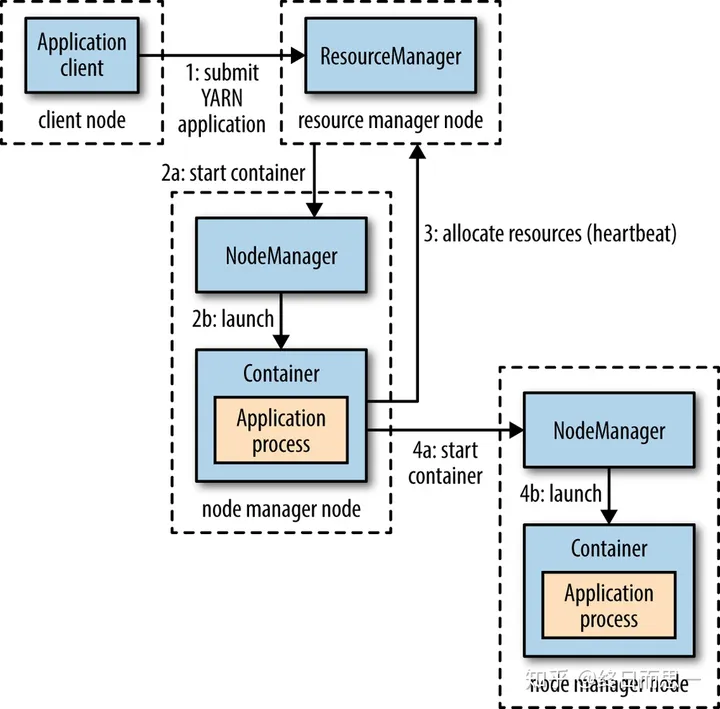
This figure shows the process of submitting a program, and we will discuss the process of each step in detail below.
The client submits an application to Yarn, assuming it is a MapReduce job.
The ResourceManager communicates with the NodeManager to allocate the first container for the application and runs the ApplicationMaster corresponding to the application in this container.
After the ApplicationMaster is started, it splits the job (i.e., the application) into tasks that can run in one or more containers. Then it applies to the ResourceManager for containers to run the program and sends heartbeats to the ResourceManager regularly.
After obtaining the container, the ApplicationMaster communicates with the NodeManager corresponding to the container and distributes the job to the container in the NodeManager. The MapReduce that has been split will be distributed here, and the container may run Map tasks or Reduce tasks.
The task running in the container sends heartbeats to the ApplicationMaster to report its status. When the program is finished, the ApplicationMaster logs out and releases the container resources to the ResourceManager.
The above is the general process of running a job.
Typical Topology of Yarn Architecture
In addition to the two entities of ResourceManager and NodeManager, Yarn also includes two entities of WebAppProxyServer and JobHistoryServer.
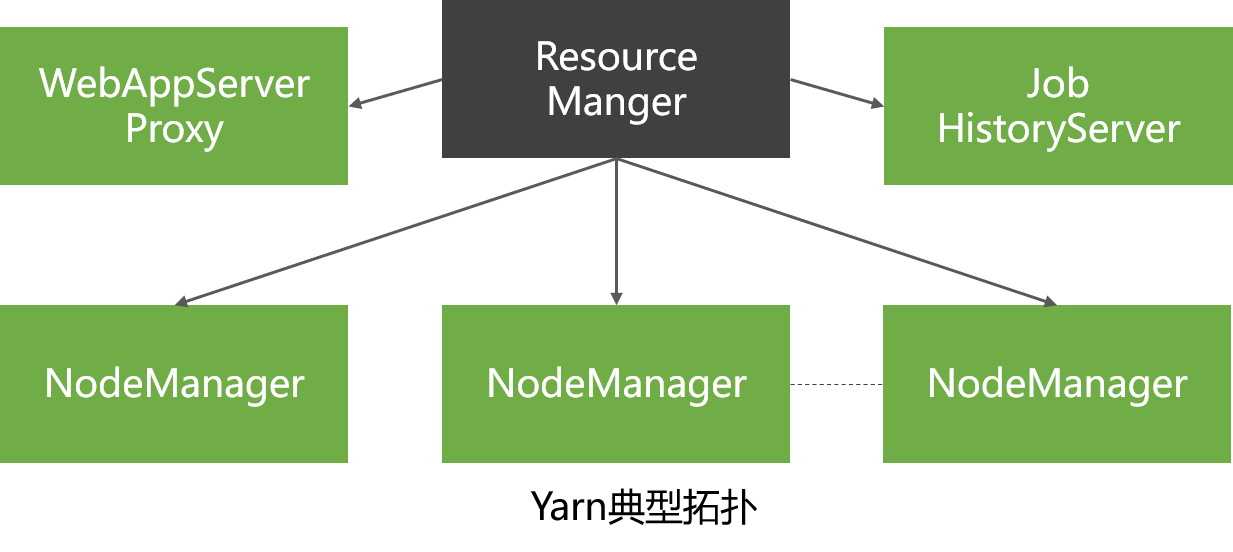
JobHistoryServer: Manages completed Yarn tasks
- The logs and various statistical information of historical tasks are managed by JobTracker.
- Yarn abstracts the function of managing historical tasks into an independent entity, JobHistoryServer.
WebAppProxyServer: Web page proxy during task execution
- By using a proxy, not only the pressure on ResourceManager is further reduced, but also the Web attacks on Yarn can be reduced.
- Responsible for supervising the entire MapReduce task execution process, collecting the task execution information from the Container, and displaying it on a Web interface.
Yarn Scheduling Strategy
Capacity Scheduling AlgorithmCapacityScheduler is a multi-user and multi-task scheduling strategy that divides tasks into queues and allocates resources in Container units.
Fair Scheduling StrategyFairScheduler is a pluggable scheduling strategy that allows multiple Yarn tasks to use cluster resources fairly.

Comments