Introduction
After reading numerous articles on WebAssembly and conducting some performance tests, I’d like to share my insights on this technology.
Is WASM Equivalent to Assembly-Level Performance?
Certainly not. The assembly in WASM does not mean actual assembly code; it is a new bytecode with its own conventions that need an interpreter to run. This interpreter is much faster than a JavaScript interpreter but still falls short of native machine code performance.
As a reference point, when JavaScript is optimized with Just-In-Time (JIT) compilation, its overall performance is roughly 1/20th of machine code. In comparison, WASM can achieve about 1/3rd of machine code performance (these figures vary depending on the context and are for reference purposes only). Even if you write code in languages like C++ and Rust, the performance you get is comparable to Java and C#, not native machine code. This explains why WASM does not demonstrate overwhelming performance advantages in all application scenarios: if you know how to optimize JS to run efficiently, it can compete with Rust in the browser environment.
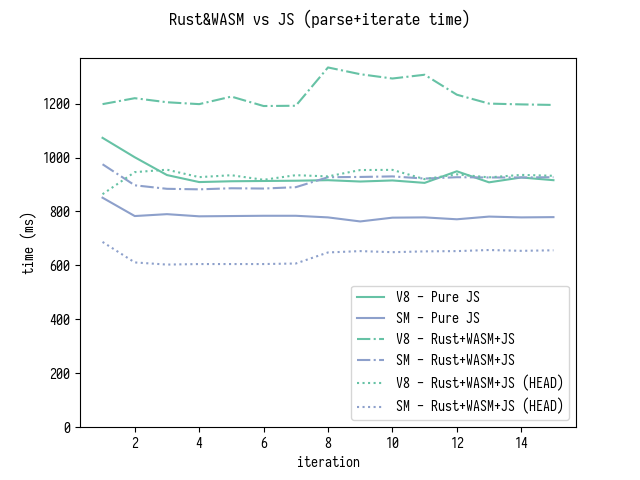
A classic case of performance comparison between WASM and JS occurred in a debate between Mozilla developers and V8 developers. Mozilla Hacks published an article titled “Optimizing Source Maps Performance with Rust and WebAssembly”, optimizing the performance of the source-map JavaScript package by five times. V8 core developer Vyacheslav Egorov responded with an article titled “You Might Not Need Rust and WebAssembly to Speed Up Your JS”, achieving astonishing optimizations in pure JS that outperformed Rust. The debate was intense, and the performance comparison chart after three rounds clearly showed Rust’s superiority, although JS managed to outperform in one round:
Additionally, Milo Yip conducted performance tests on different languages for ray tracing (a highly intensive computation task), supporting the conclusion about performance comparisons between languages and machine code. C++, Java, and JS, without specific optimizations, can represent three typical performance levels:
Language Rendering Comparison (C++/C#/F#/Java/JS/Lua/Python/Ruby)
Is WASM Faster Than JS, So It Should Be Used for Compute-Intensive Applications?
This assumption is a bit biased. WASM is still processed on the CPU. For tasks that can be highly parallelized, using WebGL for GPU acceleration is often much faster. For instance, algorithms for image processing, as I discussed in my article [“Practical WebGL Image Processing Introduction”](link to the article), can easily be several tens of times faster by using WebGL than by looping through canvas pixels in JS.
Rewriting such a nested loop in WASM to achieve a few times improvement over JS is already considered quite good. Regarding AI computations in the browser, community evaluations show that WebGL and WebMetal offer the highest performance levels, followed by WASM. Refer to this article: “Browser-Based AI Evaluations”
However, WebGL acceleration has precision issues. For example, the core of the frontend image resizing library Pica uses the Lanczos sampling algorithm. I implemented this algorithm with WebGL shaders; it is not complicated. The early version of Pica once included optional WebGL optimizations, but now it has shifted to WASM. The reason is that WASM can ensure consistent computation results with JS for the same parameters, whereas WebGL cannot. For related discussions, see Issue #114 · nodeca/pica
Moreover, there are not many compute-intensive scenarios in frontend development. Tasks like encryption, compression, and mining are not high-frequency requirements. As for potentially essential AI applications in the future, I personally have confidence in WebGPU, the next-generation standard that can fully unleash GPU potential. However, WASM is already a good alternative.
Does Embedding a WASM Function in JS Automatically Improve Performance?
Not necessarily. Modern JS engines have powerful tools for performance optimization, namely JIT (Just-In-Time compilation). Simply put, if a function like the add function in the code const add = (a, b) => a + b consistently performs integer addition, the JS engine will automatically compile machine code to compute int a + int b, replacing the original JS function. This optimization significantly enhances the performance of frequent calls to this function. This is the magic of JIT (Just-In-Time) compilation.
So, don’t assume that JS is slow and think of manually replacing such JS functions with C compiled to WASM to improve performance. Modern JS engines automatically “translate JS to C” like this for you! If you can rewrite a JS function into equivalent C code, it’s highly likely that this function, when inlined, will achieve similar performance through JIT compilation. This is probably why V8 developers confidently challenged Rust with JS in the debate I mentioned earlier.
In the article “Calls between JavaScript and WebAssembly are Finally Fast 🎉”, Lin Clark eloquently discusses the optimization process. In the end, function calls between JS and WASM are faster than non-inlined JS function calls. However, the comparison between these calls and JS functions that are inlined by JIT is not mentioned in the article.
It’s worth mentioning that Mozilla often promotes their massively optimized work, much of which might have stemmed from apparent design issues (let’s be honest; we all have our moments). For instance, the significant power-saving optimization in Firefox 70 for Mac was rooted in what exactly? A rough understanding is that the previous version of Firefox on Mac updated the window pixels for every frame! Of course, these articles contain substantial information, and I highly recommend reading the original texts after building a good foundation. It opens up a broader world and often inspires insights into software architecture design.
If WASM supports garbage collection (GC) in the future, managing object lifecycles between JS and WASM may become more complicated. For example, I recently attempted to synchronize large objects between Dart in Flutter and Java in Android, hoping to “embed some Android platform capabilities into the Flutter ecosystem.” However, this approach led to a lot of verbose and low-performance glue code. Objects had to be deep-copied asynchronously through messages, with very low controllability. Although WASM currently does not have GC, once it’s added, I have reasons to suspect that managing object lifecycles between WASM and JS will face similar challenges. However, this problem mainly concerns Mozilla and Google developers; it’s not something we need to worry about.
Is WASM Just Like Calling C from Python in Terms of Simplicity?
This question can only be answered by practical experience. For example, I have recently attempted the following:
- Calling C++ from Java classes in Android
- Calling C from Dart in Flutter
- Calling C/C++ from QuickJS, an embedded JS engine
All of these cases involve creating native objects in the engine and passing them to C/C++ functions by reference. This method is generally referred to as FFI (Foreign Function Interface), allowing native code to be embedded in language runtimes. However, if you are dealing with two different runtimes, things are not that simple. For instance, in the Quack project, which aims to bind QuickJS with Java, marshaling (similar to serialization and deserialization like JSON) has to be done between JS and Java objects; you cannot simply pass references.
So, how does it work with WASM? Essentially, WASM’s linear memory can be freely read and written by JS, without the hassle of deep copying. However, WASM does present some challenges in terms of data flow. It only supports basic data types such as integers and floats; there is no support for complex data structures like strings. Thus, for slightly more complex objects, it’s challenging to manually define corresponding structures on both the JS and WASM sides. This difficulty makes it complicated to directly perform complex object transformations using WASM. Currently, this dirty work is left to tools like wasm-bindgen, which handles complex object transformations between languages. wasm-pack uses another tool called wasm-bindgen to bridge JavaScript and Rust, among other types. However, this process is not the same as directly embedding C/C++ functions in JS runtime, as with traditional FFI compiled to machine code.
For example, if you frequently manipulate JS objects with WASM, it can almost certainly impact performance. A typical pitfall in this regard is porting OpenGL applications to WASM. For example, a function like glTexImage2D in C++ now needs to go through two layers: first, it goes from WASM to JS in the glue layer, and then from JS to WebGL API like gl.texImage2D through C++ binding. This adds an extra layer of complexity compared to directly writing the equivalent JS code. Can this approach match the performance of writing JS directly instead of two layers of glue code?
Of course, Mozilla is aware of this issue. Hence, they are exploring how to better expose Web IDL (the bindings of browser-native APIs) to WASM. In this process, they introduced the concept of WASM Interface Types: since WASM is already an intermediate bytecode, why not establish a universal Intermediate Representation (IR) specification that can unify all types across programming language runtimes? However, this specification hopes to solve problems mainly through protocolization and structured deep copying, with only the anyref type allowing passing by reference. anyref behaves somewhat like file descriptors in Unix; I won’t delve into this here.
Is WASM Part of the Frontend Ecosystem?
I do not agree with this statement. It’s essential to note that the toolchains for compiling WASM applications and the libraries they depend on have little to do with JS.
A toolchain that supports cross-compilation typically comes with libraries supporting the target platform. For example, after including <GLES2/gl2.h>, the glTexImage2D API you call is provided by the dynamic library. This API can run consistently on x86, ARM, MIPS, WASM, etc., platforms (similar to .so files in Android). Emscripten provides a set of dynamic libraries specifically for the WASM platform, compiling them into JS format. However, it only guarantees that these APIs are available; performance is a different story. Emscripten also provides many optimization suggestions for porting WebGL applications.
So, I’d like to reiterate that the dependencies and toolchains required to compile WASM applications are almost entirely unrelated to JS. JS is just a format produced by these toolchains, similar to machine code. From the perspective of JS developers, these toolchains may seem quite unfamiliar. Still, from the perspective of native application developers, everything is quite standard.
Conclusion
WebAssembly is undoubtedly a revolutionary technology, representing a new cross-platform direction, especially valuable for native application developers. However, for frontend developers, it’s just a bytecode virtual machine embedded in the browser.
I hope this article clarifies some misconceptions and provides a better understanding of WebAssembly’s capabilities and limitations. While it’s a powerful tool, it’s essential to use it judiciously and consider its advantages and trade-offs within the context of your specific use case. Remember, WebAssembly is not a magic solution that automatically improves performance in all scenarios. It’s another option in the toolkit, providing a balance between performance, development cost, and effectiveness. As the technology evolves, it will be interesting to see how it integrates further into the broader web ecosystem.
Note: This article is a translated version of the original post. For the most accurate and up-to-date information, please refer to the original source.
```